


The appeal of automatic facial and voice recognition is growing as such methods become more accurate and widely available. On the civilian side, Alipay and MasterCard deploy facial-based authentication in order to validate customer access to online financial accounts. The U.S. Department of Defense (DoD) is reportedly “shifting the use of biometrics from just law enforcement to identity and access management”—preparing to integrate these methods into Common Access Cards (CAC) for physical and logical access [1]. CACs are used by uniformed service members, DoD civilian employees, and certain contractor personnel [2]. In 2016, the DoD Defense Manpower Data Center estimated that it had issued 2.8 million CAC cards the year before—each a potential point of vulnerability for future biometric spoofing[2].
Meanwhile, several other components of DoD are seeking to implement biometric- based security and identity-verification capabilities. For example, the Defense Advanced Research Projects Agency (DARPA) is investigating the use of facial data for active (passwordless) authentication. And the Defense Information Systems Agency is researching the simultaneous use of multiple biometrics measures on mobile devices, with facial recognition included [3].
Unfortunately, facial- and voice-based authentication systems are still plagued by a wide range of impersonation attacks. Studies have shown that singular approaches to biometric authentication (such as face or voice alone) can easily be acquired from publicly available samples and manipulated with common editing tools to appear live—effectively impersonating the victim.
Many cloud-based facial- and voice-recognition systems can be defeated by the crudest impersonation attacks. So how can we defend against malicious biometric impersonation and provide better security to user authentication solutions? We propose the use of a real-time CAPTCHA system, or rtCaptcha, that combines facial and/or voice authentication requirements with a dynamic, “liveness”-based CAPTCHA challenge. Such a system prevents impersonators from knowing in advance how to circumvent standard CAPTCHA defenses.
Current Attack Methods
There are two common attack forms against bio-authentication systems: presentation attacks and compromising attacks. Depending on the usage scenario, the relevance of different attacks varies (see Figure 1). For example, if the system is used to control physical access, the integrity of the authentication device and its communication with the backend server can be guaranteed; the attacker must perform a presentation attack. In this case, employing extra sensors and better analysis of the captured data can improve the security. Examples of work in this direction
include infrared to distinguish real skin from masks [4], pulse, blood circulation, or subtle head movement as liveness detection [5], or the recent FaceID on iPhone-X, which uses both infrared and depth-sensing technology to distinguish real faces from masks.
However, for logical/remote access, since the authentication device could be jeopardized, compromising attacks become more relevant and dangerous. Not only can the attacker directly feed maliciously crafted data into the authentication server (and thus overcome physical limitations of a presentation attack), but they can also read all the sensors to learn what data the server expects, then ship this data to another device. As such, defenses that respond to these threats by employing more sensors and better analyzing data are unlikely to defeat such attacks.
The digital, remote nature of compromising attacks also means they can be automated to achieve large-scale impersonation. In fact, as noted in a 2017 report released by the Office of the Deputy Assistant Secretary of the Army for Research & Technology, recently developed tools can be used to automatically impersonate someone by generating high fidelity voice or video of that victim from stolen or publicly available samples [6].
These tools include deep learning-based speech synthesizers [7, 8]; Face2Face, a real-time facial expression reenactment tool [9]; Deep Video Protraits, a photo-realistic full 3D face expression, head position and rotation, and eye gaze and blinking synthesizer [10]; and Lip Sync, a 3D face synthesizer that syncs targeted lips from an audio source [11].
Furthermore, we tested the most popular cloud-based facial- and voice-recognition services, and our study (presented here) shows that all can be defeated by the crudest impersonation attacks; mainly because these systems are not built with sufficiently high security features in mind.
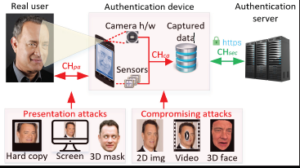
Figure 1. Attack channels specified by ISO/IEC 3017-1 standard and possible spoofing media types deployed via these channels. CHpa and CHca represent presentation and compromising attack channels respectively.
Evaluating the Security of Existing Systems
Before building a new solution, we first worked to demonstrate the severity of compromising attacks—particularly for authentication systems that are built on top of existing cloud-based facial- and voice-recognition services. We evaluated four facial recognition systems: Microsoft Cognitive Services, Amazon Rekognition, Face++ (used by Alipay), and Kairos. We also evaluated the voice-only speaker verification system from Microsoft.
We obtained sample videos of 10 different subjects from the Chinese Academy of Sciences Institute of Automation Face Anti- Spoofing Database, used extensively by biometrics researchers worldwide [12]. For each subject, we used frames from one video to enroll the individual in the test system. We then established a true-positive and true-negative baseline by presenting an image from a different video of the enrolled user and video of an entirely different user. After that, we used another video from the enrolled user as input to synthesize new, artificial 2D and 3D images of the user.
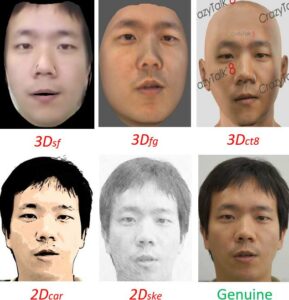
Figure 2. Genuine and spoofed versions of a full-face, frontal image of a subject from our face authentication database
Then we presented the synthesized images to the original tested system to see if any of these mock impersonations would successfully, but erroneously, authenticate that individual. The academic/publicly available tools we used to generate 3D attack images were: (a) Surrey Face Model (3Dsf), a multi-resolution 3D morphing modeling (3DMM) tool [13], (b) FaceGen (3Dfg), and (c) the demo version of CrazyTalk8 by Reallusion (3Dct8). To generate the 2D attack images, we used an online tool from Cartoonizenet to create cartoonized (2Dcar) and sketch (2Dske) photos of the user. Figure 2 presents the impersonated image from each method listed above alongside the genuine (original) photo of one test subject used in the study.The results of our evaluation against existing facial-recognition systems are presented in Table 1. All evaluated systems performed fairly well under benign situations. However, all of them fell for the synthesized image generated by Surrey Face Model (3Dsf). Even a cartoonized image (2Dcar) was good enough to impersonate a user at least seven out of 10 times.
To evaluate the robustness of the Microsoft Speaker Identification service (part of Microsoft Cognitive Services), we used data from the Automatic Speaker Verification (ASV) Spoofing Challenge dataset [14], and the data from the Deep Neural Network-based (DNN) speaker adaptation paper by Wu et al. [14]. Both datasets contain authentic and synthesized voice samples from real subjects.
For our experimental procedure, we first picked 10 random subjects—eight from the ASV dataset (Vasv) and two from the DNN dataset (Vdnn).We enrolled them with the Microsoft Speaker Identification service using their real voice, then tested the true-positive and true-negative baselines of the system using authentic voices from the enrolled user and another individual. After that, we tried to impersonate each enrolled subject using the different synthesized voices provided by the datasets. The results of our experiment can be found in Figure 3.
A few of the voice synthesis techniques from the ASV Spoofing Challenge achieved more than an 80 percent success rate when impersonating the target, while the voice that was synthesized using the DNN-based method had a 100 percent success rate. Each of these trials confirmed that singular forms of biometric authentication can be easily and repeatedly spoofed.
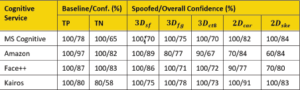
Table 1. Baseline and spoofing results of cloud-based face authentication systems.
Developing a Better Defense
Employing additional sensory methods and better analysis of the captured face/voice data can be effective against presentation attacks, but such defenses cannot defeat compromising attacks, where we have to assume the authentication device itself is compromised. The first defense would be ineffective because the attacker could fabricate the output of any number of sensors. The second defense would simply create an arms race with the attacker, as any signals that can be used by the defender to distinguish authentic face/voice data from synthesized data could be synthesized by an attacker of sufficient sophistication.
Another popular defense used in facial- and voice-based authentication is to employ some kind of liveness detection. Examples of liveness detection include prompting the user to smile (Smile-To-Pay from Alipay), blink (Blink-To-Pay from MasterCard), make a particular gesture, read some text aloud [5], or display some kind of security token to the camera of the authenticating device [15]. However, existing liveness detections based on prompting the user to perform tasks are still weak because the tasks are typically drawn from a fixed, small set (as with Smile- To-Pay and Blink-To-Pay, there is only one required task).
Once the attacker has built an accurate model of the target’s face/voice, most existing tools allow the attacker to manipulate the model to generate video/audio samples of the target doing or saying anything on the fly. As such, the biggest obstacle to the attacker remains the same—generate an authenticated model of the target’s face/voice. As for a proposed approach in which the user must use a second computing device for authentication [15], we believe that it is not feasible to require the user to carry an extra item. This approach is either not scalable or weak against replay, since the number of security tokens users can carry is usually limited.
As Figure 1 illustrates, a fraudulent model of a target’s face/voice can be developed from an attack on the transmission channel between a real user and an authentication device. However, such a model can also be created from open-source video of any person— for example, a famous individual. This heightens the vulnerability of the devices used to verify the identity of high-profile government leaders.

Figure 3. Identification accuracy of genuine voices and spoofed versions as originals.
Changing the Game with rtCaptcha
In order to truly protect current and future facial- and voice-recognition systems from cyberattacks and malicious imposters, we propose a new, practical approach that places a formidable computational burden on the attacker by combining dynamic, live detection with a randomized CAPTCHA challenge for stronger security in real time: rtCaptcha.
With rtCaptcha, we change the game between the attacker and the defender from one of endless “better synthesis vs. better detection” to one that’s known to be difficult for the attacker—solving CAPTCHA [16]. At authentication time, the server will send the authentication device a CAPTCHA, which will then be shown to the user. In order to accurately authenticate, the user needs to solve the CAPTCHA and announce the answer into the camera and/or microphone on the authentication device.
When presented with this kind of liveness detection challenge, even if the attacker already has an accurate face/voice model of the target, the attacker will need to first solve the CAPTCHA before they can synthesize video/audio of the targeted victim answering that specific challenge. As such, this will require a human attacker to stay in the loop (since automatically breaking CAPTCHA is still too slow and inaccurate), thus potentially preventing large-scale impersonation attacks.
In fact, our experiments showed that a CAPTCHA challenge that can be answered in two seconds by human users took state-of- the-art CAPTCHA-breaking systems more than 10 seconds. In other words, since humans can solve the CAPTCHA challenge at least twice as fast as an automated attacker, per our results, we could defeat automated, large-scale attacks by setting a very generous time-out for the user to correctly answer the CAPTCHA-based liveness challenge. To account for different paces of speech among human users, our time-out mechanism employs voice activity detection techniques to detect when the user starts answering the CAPTCHA. The entire workflow of rtCaptcha is summarized in Figure 4.
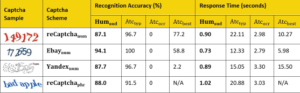
Table 2. Recognition accuracy (%) and response time (in seconds) for rtCaptcha (Humaud ), man-powered CAPTCHA solving service (Atctyp ), OCR-based CAPTCHA breaking service (Atcocr ), and ML-based (state-of-the-art) CAPTCHA-breaking tools (Atcbest ).
Evaluating rtCaptcha
Our study, completed in 2017 and presented at the 2018 Network and Distributed Systems Security Symposium, shows that rtCaptcha is a capable and robust defense against state-of-the-art CAPTCHA-breaking schemes. In particular, we evaluated both the usability and the security of the proposed rtCaptcha scheme by recruiting 31 volunteers and asking each to solve three different kinds of CAPTCHA-based liveness detection challenges. We also asked them to solve the blink- and smile-type challenges presented by our implementation of the rtCaptcha client- side application (on an Android phone); each volunteer was given three trials for each type of CAPTCHA. All of the tested CAPTCHAs are summarized in Table 2.
For all the provided CAPTCHA responses, we used the CMU Pocketsphinx [17] to convert them into text before determining, in real time, whether the response is correct.
From our user study, we found that our subjects have an overall 89.2 percent success rate in solving the CAPTCHA. The average response time is 0.93 seconds, and the maximum response time for any CAPTCHA-based challenge is below two seconds. Finally, we will note that for those who were not successful in answering the CAPTCHA-based challenge the first time, they all successfully answered the challenges within three trials (with a different challenge for each trial).
Since the security of rtCaptcha rests on the assumption that an automated attacker will take much longer to answer the CAPTCHA-based challenge than a human user, we also evaluated many state-ofthe-art CAPTCHA-breaking schemes and compared their response times with the response times of the subjects in our user study. For this study, we assumed the timeout for answering the CAPTCHA-based challenge is five seconds—more than twice the maximum response time recorded. The CAPTCHA-breaking schemes evaluated include: (a) 2Captcha (Atctyp), a cloud-based, manual CAPTCHA-solving service; (b) CaptchaTronix (Atcocr), an online, Optical Character Reading-based CAPTCHA breaking scheme; and (c) state-of-the-art schemes (Atcbest) based on character segmentation [18] and reinforcement learning [19]. We consider the cloud-based, manual CAPTCHA-breaking scheme to be a way for the attacker to scale up their attack by employing more workers, and if that approach is successful in breaking rtCaptcha, it is still possible for the attacker to launch impersonation attacks at some scale.
The response time and the accuracy of each tested scheme is presented in Table 2 alongside results from our user study for comparison. Even though some CAPTCHA-breaking schemes achieved a response time less than three seconds, the accuracy of these instances is very low. Thus, we believe a five-second time-out for the CAPTCHA-based liveness detection provides a good balance between usability and security.
Finally, we note that the security of rtCaptcha is based on the general idea of CAPTCHA (i.e., there are problems that are very easy for humans, but very difficult for computers to solve automatically), but not on the strength of individual CAPTCHA schemes. In other words, if some of the CATPCHA schemes we studied can be automatically solved in less than five seconds at some point in the future, we can always modify rtCaptcha to use more secure CAPTCHAs. We are optimistic about this solution because CAPTCHA is a very important part of the internet ecosystem (i.e., almost every important web service will need it to prevent bots from generating fake or malicious accounts).
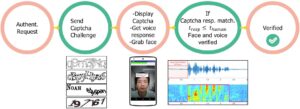
Figure 4. Process flow of rtCaptcha.
Conclusion
As the use of biometric technologies increases, user authentication methods like facial- and voice-based CAPTCHA challenges are likely to play a key role in securing DoD and other government networks from malicious actors. Defenses against impersonation must advance in tandem with new modes of biometric verification. Overall, our user study and comparative threat analysis prove that rtCaptcha constitutes a stronger, new basis against even the most scalable attacks that attempt to employ the latest audio/ visual synthesizers and state-of-the-art CAPTCHA-breaking algorithms.
Acknowledgement
All reported user studies have been approved by the Central Institutional Review Board of the Georgia Institute of Technology Office of Research Integrity Assurance.
References
1. Miller, J. (2017, December 18). DoD eyeing bigger role for biometrics in CAC replacement. Federal News Radio. Retrieved from https://federalnewsradio.com/reporters-notebook-jason-miller/2017/12/dod-eyeing-bigger-role-for-biometrics-incac-replacement/
2. Miller, J. (2016, June 15). DoD plans to bring CAC cards to an end. Federal News Radio. Retrieved from https://federalnewsradio.com/defense/2016/06/dod-plans-bring-cac-cards-end/
3. Cordell, C. (2018, January 11). DISA working on multi-factor authentication that includes how you walk, retiring director says. FedScoop. Retrieved from https://www.fedscoop.com/7-factor-authentication-coming-includes-walk-disas-lynn-says/
4. Steiner, H., Sporrer, S., Kolb, A., & Jung, N. (2016). Design of an active multispectral SWIR camera system for skin detection and face verification. Journal of Sensors, 2016, 1-16. doi:10.1155/2016/9682453
5. Holtz, C. (2016, November). Computerized system and method for determining authenticity of users via facial recognition. U.S. Patent No. 2016/0342851 A1. Washington, DC: U.S. Patent and Trademark Office.
6. Augustyn, J. (2017, November). Emerging science and technology trends: 2017–2047. Office of the Deputy Assistant Secretary of the Army. Retrieved from http://www.dtic.mil/dtic/tr/fulltext/u2/1043071.pdf
7. Shonesy, K. (2015, September 25). UAB research finds automated voice imitation can fool humans and machines. UAB News. Retrieved from http://www.uab.edu/news/research/item/6532-uab-research-finds-automated-voice-imitationcan-fool-humans-and-machines
8. Wu, Z., Swietojanski, P., Veaux, C., Renals, S., & King, S. (2015). A study of speaker adaptation for DNN-based speech synthesis. Proceedings of Interspeech 2015 International Speech Communication Association. doi: 10.7488/ds/259
9. Thies, J., Zollhofer, M., Stamminger, M., Theobalt, C., & Niebner, M. (2016). Face2Face: Real-time face capture and reenactment of RGB videos. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). doi:10.1109/ cvpr.2016.262
10. Kim, H., Garrido, P., Tewari, A., Xu, W., Thies, J., Niessner, M.,…Theobalt, C. (2018) Deep video portraits. ACM Transactions on Graphics 2018 (TOG). Retrieved from https://web.stanford.edu/~zollhoef/papers/SG2018_Deep-Video/paper.pdf
11. Suwajanakorn, S., Seitz, S. M., & Kemelmacher-Shlizerman, I. (2017). Synthesizing Obama: Learning lip sync from audio. ACM Transactions on Graphics, 36(4),1-13. doi:10.1145/3072959.3073640
12. Zhang, Z., Yan, J., Liu, S., Lei, Z., Yi, D., & Li, S. Z. (2012). A face antispoofing database with diverse attacks. 2012 5th IAPR International Conference on Biometrics(ICB). doi:10.1109/icb.2012.6199754
13. Huber, P., Hu, G., Tena, R., Mortazavian, P., Koppen, W. P., Christmas, W. J., . . . Kittler, J. (2016). A multiresolution 3D morphable face model and fitting framework. Proceedings of the 11th Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications. doi:10.5220/0005669500790086
14. Wu, Z., Kinnunen, T., Evans, N., Yamagishi, J., Hanilçi, C. & Sahidullah, M.(2015). ASVspoof 2015: The first automatic speaker verification spoofing and countermeasures challenge. Proceedings of Interspeech 2015 International Speech Communication Association.
15. Chang, A. I. S., Systems and Methods for Securely Authenticating Users via Facial Recognition. U.S. Patent No. 9,740,920 B1. (2017, August). Washington, DC: U.S. Patent and Trademark Office.
16. Uzun, E., Chung, S. P., Essa, I., & Lee, W. (2018). rtCaptcha: A real-time CAPTCHA based liveness detection system. Proceedings 2018 Network and Distributed System Security Symposium. doi:10.14722/ndss.2018.23253
17. Huggins-Daines, D., Kumar, M., Chan, A., Black, A., Ravishankar, M., & Rudnicky, A. (2006). Pocketsphinx: A free, real-time continuous speech recognition system for hand-held devices. 2006 IEEE International Conference on Acoustics Speed and Signal Processing Proceedings. doi:10.1109/icassp.2006.1659988
18. Gao, H., Yan, J., Cao, F., Zhang, Z., Lei, L., Tang, M., . . . Li, J. (2016). A simple generic attack on text captchas. Proceedings 2016 Network and Distributed System Security Symposium. doi:10.14722/ndss.2016.23154
19. Bursztein, E., Aigrain, J., Moscicki, & Mitchell, J. C. (2014). The end is nigh: Generic solving of text-based CAPTCHAs. WOOT. Retrieved from https://www.usenix.org/system/files/conference/woot14/woot14-bursztein.pdf